本篇为慧响技术角“源产控”专题系列第3篇文章。
慧响技术角“源产控”专题,将聚焦开源、国产化、自主可控三个方向的技术,以操作系统、中间件、数据库、程序应用等为粗分类,更新相关技术的发展趋势、探究技术核心的深度使用、系统总结技术整体架构,为对相关技术的学习者提供可观的资料,亦为个人同步学习总结的笔记,以飨读者。
本篇对在CentOS 8上使用Elastic Stack套件中的Elasticsearch、Kibana进行简要总结,对Elasticsearch 7.8.0的部署、认证设置与Kibana 7.8.0的配套部署进行了详细总结。未来对在CentOS 8上使用Elastic Stack相关套件,将陆续更新其使用总结、性能调优等方面的系列文章,敬请期待。
Elastic Stack介绍
提起Elastic Stack,就不得不提到ELK。ELK是三个开源软件的缩写,分别为:Elasticsearch 、 Logstash以及Kibana , 它们都是开源软件。不过现在还新增了一个Beats,它是一个轻量级的日志收集处理工具(Agent),Beats占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具,目前由于原本的ELK Stack成员中加入了Beats工具所以已改名为Elastic Stack。
Elastic Stack包含:
-
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,RESTful风格接口,多数据源,自动搜索负载等。详细可参考Elasticsearch权威指南。
-
Logstash主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为C/S架构,client端安装在需要收集日志的主机上,Server端负责将收到的各节点日志进行过滤、修改等操作在一并发往Elasticsearch上去。
-
Kibana也是一个开源和免费的工具,Kibana可以为 Logstash 和 Elasticsearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
-
Beats在这里是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、CPU、I/O等资源消耗比较高。相比 Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。
Elasticsearch 7.8的部署
方式一:YUM方式安装
输入如下命令,下载安装公共签名证书:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
在目录/etc/yum.repos.d/下新建文件elasticsearch.repo,文件内容填写如下:
[elasticsearch]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=0
autorefresh=1
type=rpm-md
添加好后,直接执行yum -y install --enablerepo=elasticsearch elasticsearch安装即可。
方式二:下载RPM包手工安装
执行如下命令,进行安装:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.8.0-x86_64.rpm;
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.8.0-x86_64.rpm.sha512;
shasum -a 512 -c elasticsearch-7.8.0-x86_64.rpm.sha512;
rpm --install elasticsearch-7.8.0-x86_64.rpm;
**注意:**若shasum提示找不到命令,请输入yum -y install perl-Digest-SHA进行依赖安装。
**提示:**鉴于Elastic网站为国外,下载速度极慢,可选择国内镜像地址,例如华为云的镜像,下载地址:https://mirrors.huaweicloud.com/elasticsearch/7.8.0/
安装完成,系统提示如下:
### NOT starting on installation, please execute the following statements to configure elasticsearch service to start automatically using systemd
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
### You can start elasticsearch service by executing
sudo systemctl start elasticsearch.service
Created elasticsearch keystore in /etc/elasticsearch/elasticsearch.keystore
[/usr/lib/tmpfiles.d/elasticsearch.conf:1] Line references path below legacy directory /var/run/, updating /var/run/elasticsearch → /run/elasticsearch; please update the tmpfiles.d/ drop-in file accordingly.
方式三:源码安装
如有更为灵活的需求,可通过官网下载Elasticsearch源码包进行部署。首先需建立用户属组:
groupadd -g 888 elasticsearch;
useradd -g elasticsearch -m -u 888 elasticsearch;
后通过官网或镜像下载地址下载,解压到需要部署的文件夹:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.8.0-linux-x86_64.tar.gz;
tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz -C /usr/share/;
mv /usr/share/elasticsearch-7.8.0/ /usr/share/elasticsearch;
chown -R elasticsearch:elasticsearch /usr/share/elasticsearch;
Elasticsearch 7.8的配置
部署完成后就进入配置环节了,在配置之前我们需要知道的是进程文件和配置文件所在地。通过上述方式一、二安装,进程文件路径在/usr/share/elasticsearch,配置文件路径在/etc/elasticsearch。通过上述方式三安装,进程文件路径在解压文件路径,例如示例给出的/usr/share/elasticsearch,配置文件在进程文件路径下的config文件夹内。
在配置文件路径下有一个文件叫jvm.options,修改其中的-Xms、-Xmx两行参数来调整jvm的初始化堆大小以及最大堆大小。该值建议设置为操作系统内存的40%~50%。注:-Xms与-Xmx相同。例:若虚拟机内存为8G,可设置为如下参数:
-Xms4g
-Xmx4g
或者
-Xms4096m
-Xmx4096m
在配置文件路径下有一个文件叫elasticsearch.yml文件,对该文件进行配置以使集群启动:
# 集群名称,集群中所有节点统一
cluster.name: Elasticsearch-Cluster
# 当前节点名,自定义但集群内不允许重复
node.name: node-1
node.attr.rack: r1
# 下方数据和日志存放路径请按照实际情况修改路径
# 通过方法一、二安装,默认路径已存在,通过方法三安装,请指定存在的路径
path.data: /var/lib/elasticsearch
path.logs: /var/logs/elasticsearch
bootstrap.memory_lock: true
# 当前节点内网IP地址,虽也可以设置为0.0.0.0但建议还是按此设置
network.host: 10.66.66.1
http.port: 9200
# 集群中所有节点地址
discovery.seed_hosts: ["10.66.66.1", "10.66.66.2","10.66.66.3"]
# 集群中所有节点名,应与集群所有节点的node.name一致
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
另外,在启动Elasticsearch 7.8之前需先做些准备工作。首先编辑文件/etc/security/limits.conf,在尾部增加如下配置:
elasticsearch soft nofile 100000
elasticsearch hard nofile 100000
elasticsearch soft memlock unlimited
elasticsearch hard memlock unlimited
elasticsearch soft nproc 4096
elasticsearch hard nproc 4096
编辑文件/etc/sysctl.conf,根据文件内已有内容,调整或新增如下配置:
vm.swappiness=10
vm.max_map_count=262144
添加完成后,执行sysctl -p。
最后修改/etc/hosts文件,增加Elasticsearch集群主机名,例如:
10.66.66.1 node-1
10.66.66.2 node-2
10.66.66.3 node-3
Elasticsearch内置Java,无需再在系统层再次部署Java。
完成配置后即可启动,方法一、二可通过systemctl命令进行启停:
systemctl start elasticsearch;
systemctl stop elasticsearch;
systemctl restart elasticsearch;
如需开启开机自启,可通过如下命令开启:
systemctl daemon-reload;
systemctl enable elasticsearch;
方法三启动可通过如下命令进行启停:
# 启动
/usr/share/elasticsearch/bin/elasticsearch -d -p /usr/share/elasticsearch/pid;
# 停止
esid=$(cat /usr/share/elasticsearch/pid && echo);
kill -SIGTERM $esid;
启动后可以执行如下命令,查看启动日志、集群节点发现、主节点选举是否正常:
# 路径请注意:1. 按照配置文件设置的日志存放路径寻找;2. 按照实际集群名输入日志文件名
tail -f /var/logs/elasticsearch/Elasticsearch-Cluster.log;
# 按照方法一、二安装后也可以通过如下命令查看Elasticsearch进程情况
systemctl status elasticsearch;
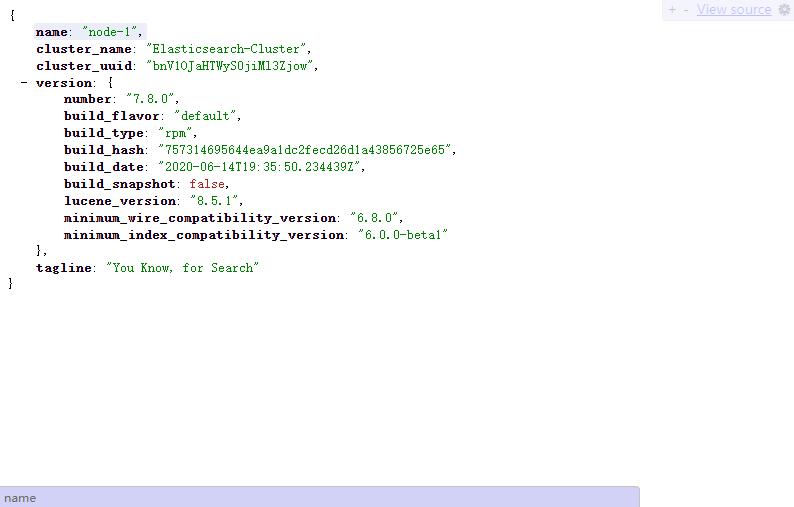
也可以通过如下网址浏览器或curl命令访问直接获取Elasticsearch返回的集群健康检查信息:
curl -XGET http://node-1:9200/_cluster/health?pretty
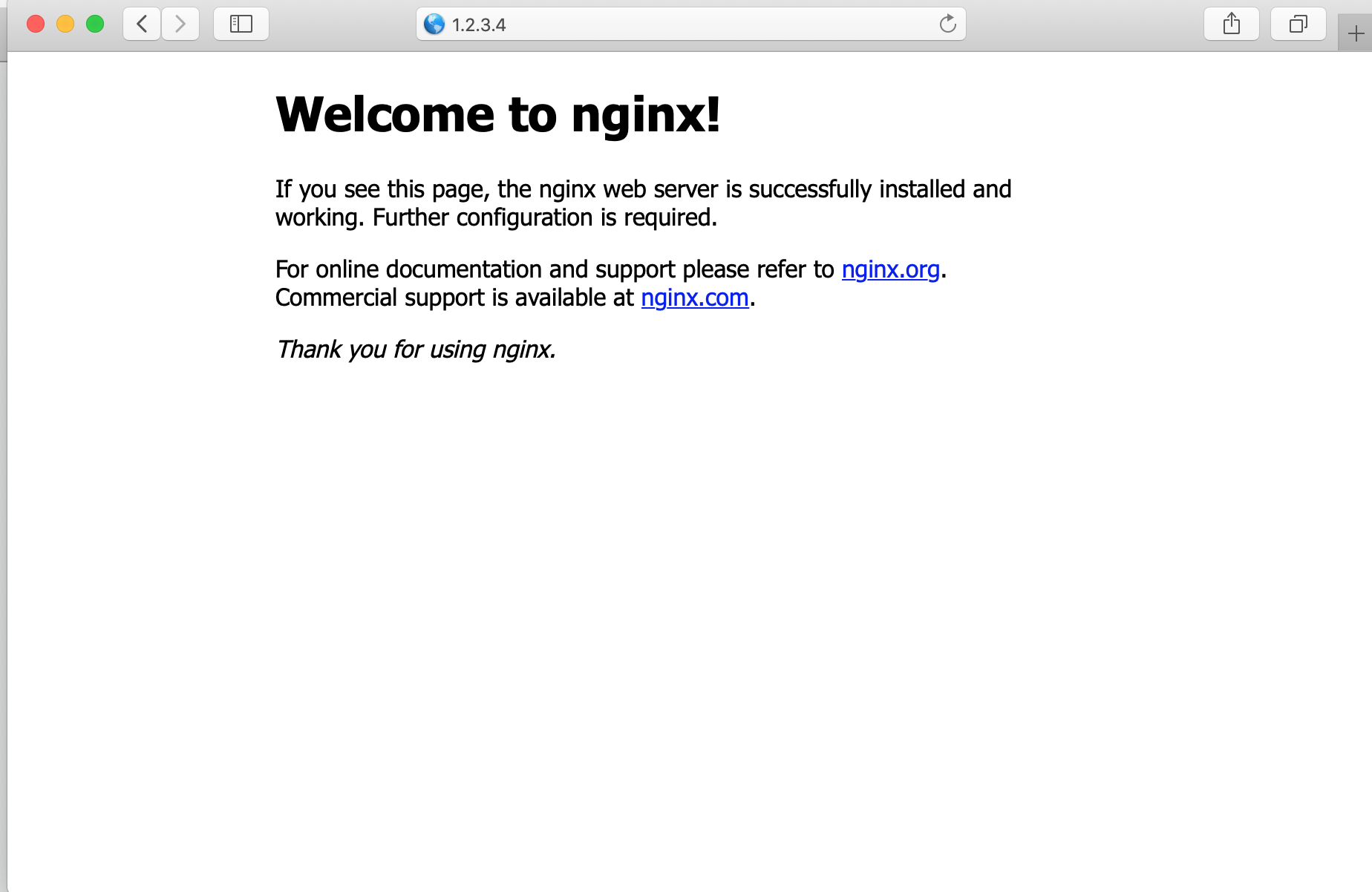
也可以在浏览器直接访问机器的9200端口,可展示如下页面:
Elasticsearch 7.8的认证功能配置
Elasticsearch默认启动后,9200端口通过设定的Host IP是可以随意访问的,这十分不安全。为了保证一定的安全性,我们可以修改elasticsearch.yml文件里http.port字段,修改默认端口,以及增加访问时必须帐密认证访问。
自Elasticsearch 6.8开始,Elastic将部分X-Pack付费功能免费开放使用,其中就有基础认证功能,因此在Elasticsearch 6.8以后,可直接使用Elasticsearch自带的认证功能。而之前的版本,则需要一个开源插件叫做elasticsearch-http-basic,作者仓库地址:https://github.com/Asquera/elasticsearch-http-basic 。然而目前此仓库已封版不再更新,因此建议如需使用Elasticsearch,不要使用Elasticsearch 6.8以前的版本。
接下来我们配置Elasticsearch 7.8的认证功能,首先在某一台集群节点中,进入进程文件路径,执行如下命令,创建一个证书颁发机构:
bin/elasticsearch-certutil ca;
一路回车即可,中间有设置CA的密码,无需设置。完成后将在进程文件路径目录生成文件elastic-stack-ca.p12。后继续在该台已生成证书颁发机构的集群节点继续执行如下命令,创建一个证书与私钥:
bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12;
一路回车即可,中间有设置证书的密码,无需设置。完成后将在进程文件路径目录生成文件elastic-certificates.p12。完成生成后,将该文件拷贝到其他机器的相同路径,集群所有机器修改两个文件的属组:
chown -R elasticsearch:elasticsearch *.p12;
集群所有机器建立软连接到配置文件路径下,示例如下,具体路径请修改为实际路径:
ln -s /usr/share/elasticsearch/elastic-certificates.p12 /etc/elasticsearch/elastic-certificates.p12;
ln -s /usr/share/elasticsearch/elastic-stack-ca.p12 /etc/elasticsearch/elastic-stack-ca.p12;
配置elasticsearch.yml:
# 设置集群互信通信端口9300
transport.port: 9300
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization
# 开启X-Pack的安全认证
xpack.security.enabled: true
# 开启X-Pack的集群内互信安全认证,与上面安全认证开关同步必开
xpack.security.transport.ssl.enabled: true
# 验证模式为证书模式
xpack.security.transport.ssl.verification_mode: certificate
# 配置证书路径
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
# 如果需要启用SSL/TLS通过HTTPS访问ES集群,再添加如下配置
xpack.security.http.ssl.enabled: true
xpack.security.http.ssl.keystore.path: elastic-certificates.p12
xpack.security.http.ssl.truststore.path: elastic-certificates.p12
xpack.security.http.ssl.client_authentication: none
修改discovery.seed_hosts字段配置,增加集群互信通信端口9300,例如:
discovery.seed_hosts: ["10.66.66.1:9300", "10.66.66.2:9300","10.66.66.3:9300"]
完成配置后,重启Elasticsearch进程即可。后进行内置用户认证密码的设置,在某一台集群节点中,进入进程文件路径,执行如下命令:
bin/elasticsearch-setup-passwords interactive;
这里给Elasticsearch中内置用户创建密码,其内置用户有:
- elastic:拥有 superuser 角色,是内置的超级用户,它可以做任何事情。
- kibana:拥有 kibana_system 角色,是Kibana用来连接Elasticsearch并与之通信的。Kibana服务器以该用户身份提交请求以访问集群监视API和.kibana索引不能访问 index。
- logstash_system:拥有logstash_system角色。是Logstash在Elasticsearch中存储监控信息时使用。
- beats_system:拥有 beats_system 角色。是Beats在Elasticsearch中存储监控信息时使用。
- apm_system:APM服务器在Elasticsearch中存储监视信息时使用的用户。
- remote_monitoring_user:Metricbeat用户在Elasticsearch中收集和存储监视信息时使用。 它具有remote_monitoring_agent和remote_monitoring_collector内置角色。
完成此步设置,再使用HTTP/HTTPS协议通过9200端口访问时,就需要帐密了。输入帐密即可访问。curl也可,命令测试示例如下,例如用户名为elastic,密码为ESabc+2333:
curl -uelastic:ESabc+2333 -XGET http://node-1:9200/_cluster/health?pretty
Kibana的部署与配置
Kibana的部署配置比较简单,安装方式类似Elasticsearch,具体可自行选择,本节不再赘述,使用方法二,执行如下命令,进行安装:
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.8.0-x86_64.rpm;
shasum -a 512 kibana-7.8.0-x86_64.rpm;
rpm --install kibana-7.8.0-x86_64.rpm;
**注意:**若shasum提示找不到命令,请输入yum -y install perl-Digest-SHA进行依赖安装。
**提示:**鉴于Elastic网站为国外,下载速度极慢,可选择国内镜像地址,例如华为云的镜像,下载地址:https://mirrors.huaweicloud.com/kibana/7.8.0/
按上述方式安装后其进程文件路径在/usr/share/kibana,配置文件路径在/etc/kibana。
修改/etc/kibana/kibana.yml文件为如下配置:
server.port: 5601
server.host: "0.0.0.0"
# 设置Elasticsearch集群地址,方便Kibana做容灾管理
elasticsearch.hosts: ["https://node-1:9200","https://node-2:9200","https://node-3:9200"]
kibana.index: ".kibana"
# 国际化设置,设置为中文
i18n.locale: "zh-CN"
# 开启X-Pack的安全认证
xpack.security.enabled: true
# Elasticsearch内置账户密码
elasticsearch.username: "kibana"
elasticsearch.password: "ESabc+2333" # 设置内置账户密码时kibana账户的密码
# Kibana SSL/TLS访问开启,若无需配置SSL/TLS,可忽略
server.ssl.enabled: true
server.ssl.key: /etc/kibana/kibana-certificates.key
server.ssl.certificate: /etc/kibana/kibana-certificates.cer
server.ssl.certificateAuthorities: /etc/kibana/kibana-certificates-ca.cer
server.ssl.clientAuthentication: none
# Elasticsearch如开启SSL/TLS访问,则需要配置如下两条规则
elasticsearch.ssl.verificationMode: certificate
elasticsearch.ssl.certificateAuthorities: /etc/kibana/kibana-certificates-ca.cer
上述Kibana配置中SSL/TLS的认证有点小插曲需要说明,由于Kibana现在不支持.p12文件的加密认证方式,若目前没有SSL/TLS安全机构认可的签发证书,但仍需要启用SSL/TLS,此时需要我们将.p12文件转换后使用配置。具体操作如下:
openssl pkcs12 -in elastic-certificates.p12 -nocerts -nodes > kibana-certificates.key
openssl pkcs12 -in elastic-certificates.p12 -clcerts -nokeys > kibana-certificates.cer
openssl pkcs12 -in elastic-certificates.p12 -cacerts -nokeys -chain > kibana-certificates-ca.cer
将生成的几个文件放置在合适的路径,例如上述配置将这几个文件放置在了/etc/kibana/路径下,后调用即可。
**注意:**仍然建议使用域名向安全机构申请认可的签发证书后配置Kibana的SSL/TLS选项,因为自签发证书浏览器不认为是安全的,仍有安全风险,请注意。
完成配置后即可启动,可通过systemctl命令进行启停:
systemctl start kibana;
systemctl stop kibana;
systemctl restart kibana;
如需开启开机自启,可通过如下命令开启:
systemctl daemon-reload;
systemctl enable kibana;
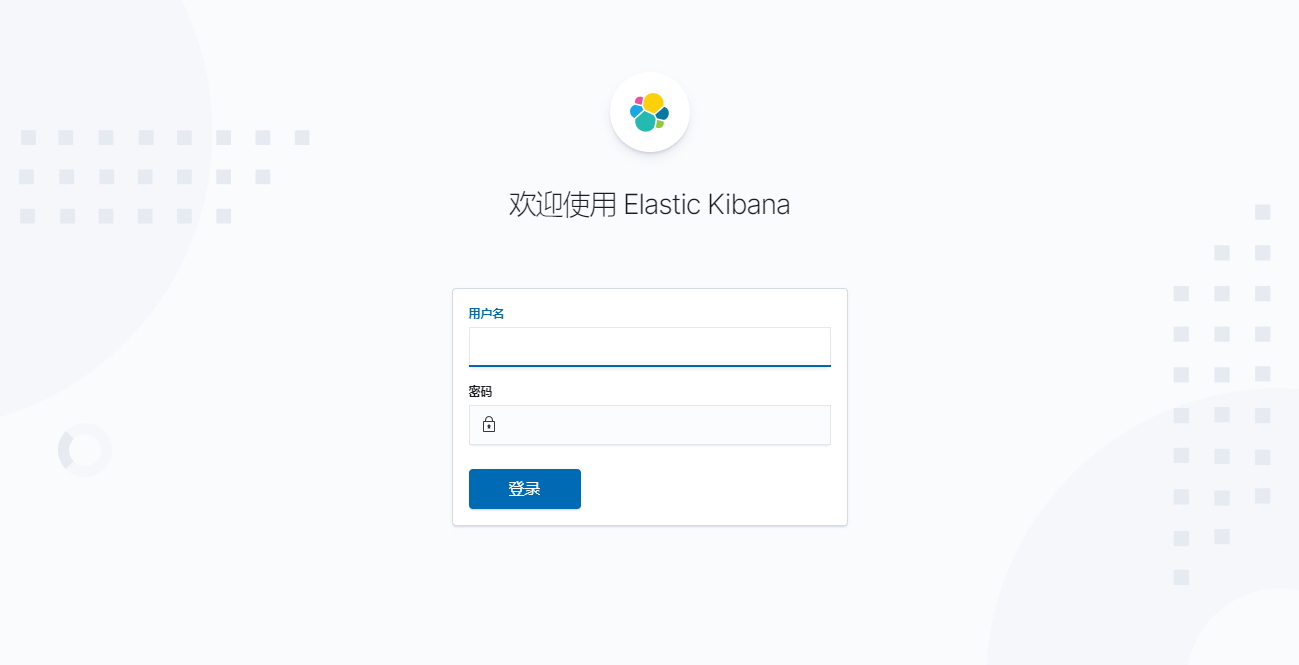
启动后通过浏览器访问即可,可通过输入内置用户访问Kibana,例如用户名为elastic,密码为ESabc+2333:
]]>