最近工作需要研究日志集中管理的内容,盯上了ELK+Filebeat的解决方案。为了以后能够持续学习,现就此做个总结和笔记。
注意:本文首次撰写于2018-11-19,最近修改时间为2018-11-19,请注意相关程序的可用性与安全性。
ELK与Filebeat协议栈介绍及体系结构
ELK 其实并不是一款软件,而是一整套解决方案,是三个软件产品的首字母缩写,Elasticsearch,Logstash 和 Kibana。这三款软件都是开源软件,通常是配合使用,而且又先后归于 Elastic.co 公司名下,故被简称为 ELK 协议栈,见下图。
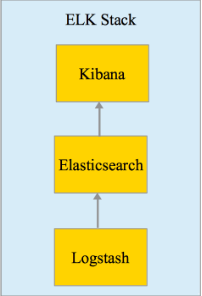
ElasticSearch
Elasticsearch 是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎,使用 Java 语言编写。目前,最新的版本是 6.5.0。
主要特点
- 实时分析
- 分布式实时文件存储,并将每一个字段都编入索引
- 文档导向,所有的对象全部是文档
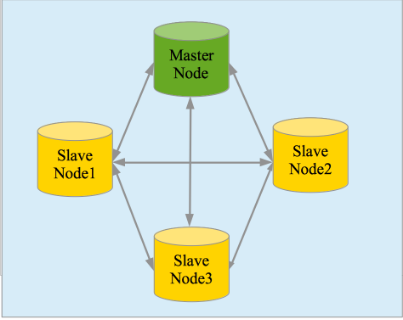
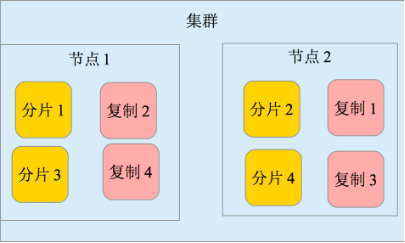
- 高可用性,易扩展,支持集群(Cluster)、分片和复制(Shards 和 Replicas)。见下二图
- 接口友好,支持 JSON
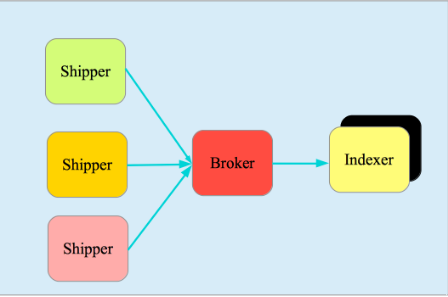
Logstash
Logstash 是一个具有实时渠道能力的数据收集引擎。使用 JRuby 语言编写。其作者是世界著名的运维工程师乔丹西塞 (JordanSissel)。目前最新的版本是 6.5.0。
主要特点
- 几乎可以访问任何数据
- 可以和多种外部应用结合
- 支持弹性扩展
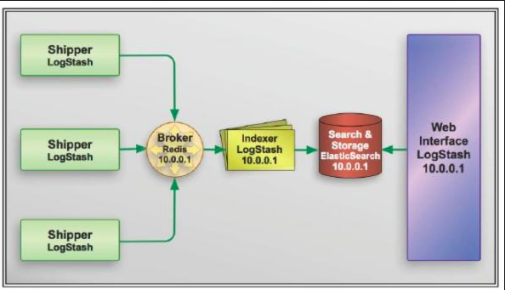
它由三个主要部分组成,见下图:
- Shipper-发送日志数据
- Broker-收集数据,缺省内置 Redis
- Indexer-数据写入
Kibana
Kibana 是一款基于 Apache 开源协议,使用 JavaScript 语言编写,为 Elasticsearch 提供分析和可视化的 Web 平台。它可以在 Elasticsearch 的索引中查找,交互数据,并生成各种维度的表图。目前最新的版本是 6.5.0,简称 Kibana 6。
Filebeat
Filebeat是一个以logstash-forwarder的源码为基础的日志收集器,以客户端的形式安装在要被监控日志的服务器上,监控日志目录或日志文件(以查看文件尾的形式),然后将日志数据转发给Logstash解析或者Elasticsearch建立索引。这样就可以在多台待收集日志的机器上部署Filebeat,然后在另一台服务器上部署Logstash或者Elasticsearch收集各个Filebeat发过来的日志,方便扩展和维护。目前最新的版本是 6.5.0。
Filebeat的工作原理如下:Filebeat启动后,会开启若干个“prospector”搜索配置路径下的日志,针对每一个日志会开启一个“harvester”不停地监控、收集日志中的新增部分,然后把收集到的日志发送给”spooler”,“spooler”负责整合数据信息然后将信息发送到特定的位置(如Logstash或者Elasticsearch)。
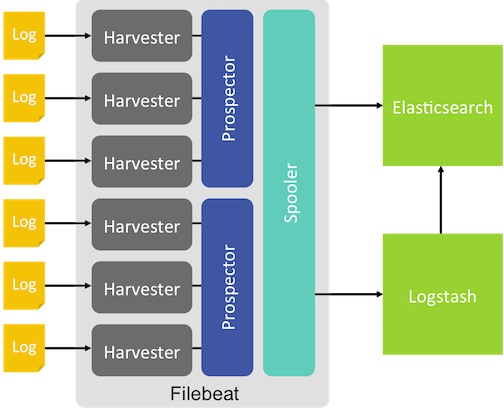
体系结构
完整的ELK 协议栈体系结构见图5。基本流程是Shipper 负责从各种数据源里采集数据,然后发送到Broker,Indexer 将存放在Broker 中的数据再写入Elasticsearch,Elasticsearch 对这些数据创建索引,然后由Kibana 对其进行各种分析并以图表的形式展示。
ELK 三款软件之间互相配合使用,完美衔接,高效的满足了很多场合的应用,并且被很多用户所采纳,诸如路透社、脸书(Facebook)、StackOverFlow 等等。
ELK与Filebeat部署
环境
- 两台 CentOS 7.1
- elasticsearch-2.4.1
- kibana-4.6.1
- logstash-2.4.0
- filebeat-1.3.1
过程
- 安装 JDK
- 安装 Nginx
- 安装与配置 Elasticsearch
- 安装与配置 Kibana
- 安装与配置 Logstash
- 安装与配置 filebeat
- 访问环境
安装 Java 环境
-
https://www.oracle.com/technetwork/cn/java/javase/downloads/index.html中下载java jdk安装包建议使用JDK1.8
-
解压到
/usr/local/jdk目录下 -
在
/etc/profile文件中追加:export JAVA_HOME=/usr/local/jdk export CLASS_PATH=$JAVA_HOME/lib export PATH=$JAVA_HOME/bin:$PATH -
使设置的环境变量生效。
source /etc/profile
安装 Nginx
-
直接
yum安装$ yum install nginx -
修改
/etc/nginx/conf.d/default.conf文件,如下:server { listen 80; server_name _; location / { proxy_pass http://127.0.0.1:5601/; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; } error_page 404 /404.html; location = /40x.html { } error_page 500 502 503 504 /50x.html; location = /50x.html { } }其中,
http://127.0.0.1:5601/是使Nginx反向代理了内部kibana的访问地址。 -
启动
nginx,可以在安装完kibana之后再启动# 测试配置是否正常 $ nginx -t # 启动 $ /etc/init.d/nginx start
安装 Elasticsearch
-
在
https://www.elastic.co/downloads中下载Elasticsearch的安装包。 -
解压,并移动到
/usr/local/elasticsearch目录下。$ tar xvf elasticsearch-2.4.1.zip $ mv elasticsearch-2.4.1 /usr/local/elasticsearch -
修改
/usr/local/elasticsearch/config/elasticsearch.yml,来更改监听端口,监听127.0.0.1,提高安全性。# 如下更改 network.host: 127.0.0.1 -
启动(会有报错)
$ cd /usr/local/elasticsearch/ $ bash bin/elasticsearch -d # 会有报错,信息如下: Exception in thread "main" java.lang.RuntimeException: don't run elasticsearch as root.
-d是让es保持后台运行。
报错信息提示我们es无法用root用户启动,所以可以创建elk用户,来启动es
安装 kibana
-
在
https://www.elastic.co/downloads中下载kibana的安装包。 -
解压,并移动到
/usr/local/kibana目录下。 -
修改
/usr/local/kibana/config/kibana.yml,来更改监听端口,监听127.0.0.1# 修改如下 server.host: "127.0.0.1" -
启动,观察
/usr/local/kibana/nohup.out是否有报错信息$ cd /usr/local/kibana $ nohup bin/kibana &
安装与配置 Logstash
-
在
https://www.elastic.co/downloads中下载Logstash的安装包。 -
解压,并移动到
/usr/local/logstash目录下。 -
验证服务可用性
$ cd /usr/local/logstash $ bin/logstash -e 'input { stdin { } } output { stdout {} }' Settings: Default pipeline workers: 2 Pipeline main started # 任意输入,看输出是否正常,如下: hello 2016-10-13T10:07:01.502Z satezheng hello # CTRL-D 退出
接下来我们进行Logstash的配置。
我们需要配置 Logstash 以指明从哪里读取数据,向哪里输出数据。这个过程我们称之为定义 Logstash 管道(Logstash Pipeline)。
通常一个管道需要包括必须的输入(input),输出(output),和一个可选项目 Filter
配置 ssl
客户端和服务器之间通信使用ssl来认证身份,更加安全。
-
修改
/etc/pki/tls/openssl.cnf文件# 找到 [v3_ca] 段,添加下面一行,保存退出。 subjectAltName = IP: logstash_server_ip -
生成
srt文件$ cd /etc/pki/tls $ openssl req -config openssl.cnf -x509 -days 2650 -batch -nodes -newkey rsa:2048 -keyout private/logstash-forwarder.key -out certs/logstash-forwarder.crt -
发送
srt文件到客户端$ cd /etc/pki/tls $ scp certs/logstash-forwarder.crt 客户端IP:/etc/pki/tls/certs
配置 Logstash 管道文件
生成一个logstash.conf文件,在这里我们准备处理apache的log
input {
file {
path => "/private/var/log/apache2/www.myserver.com-access_log"
start_position => beginning
ignore_older => 0
sincedb_path => "/dev/null"
}
}
filter {
grok {
match => { "message" => "%{IPORHOST:clientip} - %{USER:auth} \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:response} (?:%{NUMBER:bytes}|-)"}
}
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss +0800" ]
}
}
output {
elasticsearch {}
stdout {}
}
为了这个配置文件,费了很大精力,网上很多教程都和我的实际情况不相符合。关键点说明如下:
start_position => beginning告诉logstash从我的log文件的头部开始往下找,不要从半中间开始。
ignore_older => 0告诉logstash不要管我的log有多古老,一律处理,否则logstash缺省会从今天开始,就不管老日志了。
sincedb_path => "/dev/null"这句话也很关键,特别是当你需要反复调试的时候,因为logstash会记住它上次处理到哪儿了,如果没有这句话的话,你再想处理同一个log文件就麻烦了,logstash会拒绝处理。现在有了这句话,就是强迫logstash忘记它上次处理的结果,从头再开始处理一遍。
filter下面的grok里面的match,网上教程一般是这么写的:
match => { "message" => "%{COMBINEDAPACHELOG}" }
但是当我这么写的时候,总是处理不了我的log,我的log其实就长这个样子:
127.0.0.1 - - [02/May/2016:22:11:28 +0800] "GET /assets/aa927304/css/font-awesome.min.css HTTP/1.1" 200 27466
查源代码,官方是这么写的:
COMMONAPACHELOG %{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{NUMBER:bytes}|-)
COMBINEDAPACHELOG %{COMMONAPACHELOG} %{QS:referrer} %{QS:agent}
后面的combined引用前面的common,而问题就出在这个USER:ident上。
我在https://grokdebug.herokuapp.com/反复验证,最后发现只要把这个USER:ident改成-就行了,所以就有了我上面的写法。
接下来用了一个date filter,这是因为如果不用这个date filter的话,它会把处理log的时间认为是用户访问网页的时间来产生表格,这样在kibana里看上去怪怪的,所以加这么一个filter,但就是加这么一个简单的filter,也出现了问题,处理失败,因为网上的教程里一般都是这么写的:
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
}
区别就在最后一个Z上,我的时区字符串是+0800,怎么也匹配不上这个Z,索性一怒之下直接用+0800代替,也就过关了。
过程中不停地访问如下网址验证elasticsearch的结果:
http://localhost:9200/logstas...
注意URL中那个时间,一开始的时候我们就用处理日志的时间访问就可以,但当加上date filter后就不一样了,如果你还用当前日期的话,会一无所得,改成log里的时间才会看到结果,因为index日期变了。
然后就是你需要一遍一遍地清空elasticsearch里的数据,进行调试:
curl -XDELETE 'http://localhost:9200/_all'
清空完了以后你再执行logstash,就把新数据又灌进去了:
logstash agent -f ~/logstash/logstash.conf
启动
-
后台运行。
$ cd /usr/local/logstash $ nohup bin/logstash -f conf/ &
安装Filebeat(日志收集服务器端)
-
下载和安装
https://www.elastic.co/products/beats/filebeat
目前最新版本 6.5.0
这里选择 LINUX 64-BIT 即方式一
方式一:源码
wget https://download.elastic.co/beats/filebeat/filebeat-6.5.0-x86_64.tar.gz tar -zxvf filebeat-6.5.0-x86_64.tar.gz方式二:deb
curl -L -O https://download.elastic.co/beats/filebeat/filebeat_6.5.0_amd64.deb sudo dpkg -i filebeat_6.5.0_amd64.deb方式三:rpm
curl -L -O https://download.elastic.co/beats/filebeat/filebeat-6.5.0-x86_64.rpm sudo rpm -vi filebeat-6.5.0-x86_64.rpm方式四:MAC
curl -L -O https://download.elastic.co/beats/filebeat/filebeat-6.5.0-darwin.tgz tar -xzvf filebeat-6.5.0-darwin.tgzfilebeat代替之前的ogstash-forwarder
-
在
https://www.elastic.co/downloads/beats/filebeat下载 -
解压并放到
/usr/local/filebeat目录下 -
修改
filebeat.yml$ cd /usr/local/filebeat $ vim filebeat.yml写入:
filebeat: prospectors: - paths: - /var/log/* input_type: log document_type: log registry_file: /var/lib/filebeat/registry output: logstash: hosts: ["服务端IP:5044"] tls: certificate_authorities: ["/etc/pki/tls/certs/logstash-forwarder.crt"] shipper: logging: files: rotateeverybytes: 10485760 # = 10MB -
启动
$ cd /usr/local/filebeat $ nohup ./filebeat -e -c filebeat.yml &